variance formula

= Sample dispersion ()

= One observation value (터균균))
인기글





= Average of all observations ( 터터의데 )

= Number of observations (number of observations)

감지된 언어가 없습니다.
입력 언어를 확인해 주세요.
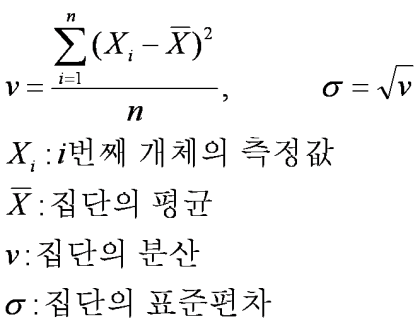
deviation.
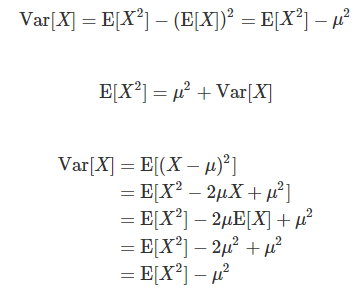
deviation.

deviation.

# # Distributed= Version ########################################## ## ## ## ## ## from the timeout port listVault= ListViewVieworsf List[logat]#num_filter=Number_file_file_file_priority= [19,21,049,100,21,40,21,24,049,0.412,100.1,40.414、24、9,9,9,9,9,8,8,8,8,8,8,8,8,8,8,8,8,8,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,11,1, 1# data average for data average number of data average number (xs) ->logat:@\\\\\n size (xs) / lumber (xs) / lumber(xs 公式def sum_of_squares(v:Vector) -> float:””Returns v_1 * v_1 +··· + + v_n * v_n”””return dot(v, v)# 백터의 내적def dot(v: Vector, w: Vector) -> float:”””Computes v_1 * w_1 + ··· + + v_n * w_n””” assert len(v) == len(w), “vectors must be same length”return sum(v_i * w_i for v_i, w_i in zip(v, w))############################################################ “range” already means something in Python, so we’ll use a different name# 데이터 범위를 구하는 함수def data_range(xs: List[float]) -> float:return max(xs) – min(xs)assert data_range(num_friends) == == 99 # 확인# 편차를 구하는 함수def de_mean(xs: List[float]) -> List[float]:”””Translate xs by subtracting its mean (so the result has mean 0)””” x_bar = mean(xs)return [x – x_bar for x in xs]# 분산 구하는 함수def variance(xs: List[float]) -> float:”””Almost the average squared deviation from the mean””” # 분산에는 두개 이상의 요소가 필수 assert len(xs) >= 2, “variance requires at least two elements” #확인 n = len(xs) deviations = de_mean(xs)return sum_of_squares(deviations) / (n – 1)assert 81.54 < variance(num_friends) < 81.55 #확인

平方和 = ko.wikipedia.org/wiki/%EC%A0%9C%EA%B3%B1%ED%95%A9
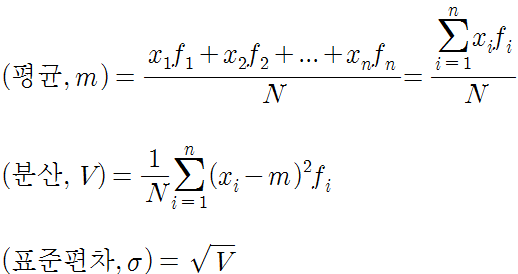
square Japanese – Wiki-style, we have all encyclopedia square Japanese Wiki, our encyclopedia.square sum of the square sum of the size of each case, the total number of deviation between each case, the variable value of each case, the variable value of each case. {\displaystyle SS=\Sigma (Y-{\overline{Y})^{2}性質[ Edit] square Japanese is larger than 0.If all cases of all cases in the sample is equal to zero.If square Japanese are 0, the same as the Y value in the sample.split [Edit]Distributed Analysis [Edge]Distributed Analysis… ko.wikipedia.org
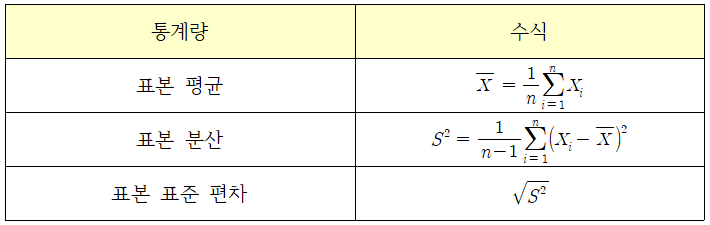
standard deviation= Population standard deviation= Population size= Values of each population= Population average= Population average= Population average################################################################################################ == == 6quantile=quaternionContract Thompson:// Blame him Benikuni.%82% in Europe and America/Benikuni/%, not 6%.Eighty-four percent, nine percent, and 88 percent 98.4 minutes to the fourth level of the base router widget 3 to the second level of the second (Q) of the same value of 4 minutes (Q) (Q) of the respective points of the respective items.Q2.4 minutesDescription of the first four minutes (Q1) accumulated by 25 percent of the total number of values (Q1) zetawiki.comA formula for exploring the relevance of covariance data to each other.= Relationship between variable a and variable y=data value of x Each data=data value of y Each data=mean of x average=mean of y average=Number of data values (터수))| Integrated |=0 is similar to distributed|→0 is closer to distributed|00.| compare the association of data sets and num_filter that is less related to the distributed|←00 is less than the same|Covariance|=0The closer all data are to match|Covariance|→0, the more relevant it is.|Covariance|The further you go to ←00, the less relevant you are.Compare the association between a dataset called daily_minutes and a set of num_friendscorrelation$S_{xy}:\covariance $Sxy:covariance $\combi{S}_x,\combi{S}_y:\standard deviation $Sx, Sy:standard deviation|correlation coefficient|<=1 related|correlation coefficient|>1 not related|correlation coefficient|<=1 related|correlation coefficient|>1 not related# # [import matplotlib]Import .pdat: How do you want to specify the default_module: How to the default_dimensional__>:logat:logat:logat:> if stdev_x > 0 and stdev_y >0:rror if you return distributed with the distributed (y, ys) /stDevice_yelopt0 #; the correlation is zero <24) < 0.25px 0.24 < correlation(num_friends, daily_hours) < 0.25px = num_friends.index(100) # outliernum_friends_good = [i != outlier] daily_minute if i!= [i に x 、 dmin enumber (dmin (dometer) ] dmin (dometaily_hers)es_good]>0.57 < correlation (num_friends_good, daily_minutes_good)< 0.58 > 0.57 < correlation (num_friends_good, daily_hours_good)< 0.58plt.plt.axis([-5,105,-5,105])plt.xlabel(“友達のplabel”#offriends”)plates”)plate”)plates”)plate”)plates”)Pl%20% 20% 20% 20% 20% (N) %20% 20% 20% 20% 20% 2.5 0.2 0.2 0.5 0.0 2.0 2.5 0.0 2.0 O,000 2,000 (N) That’s it.Distributed and standard deviation measurements must be proportional to the scattering of data (if data is larger, if data is clustered together).The measurement value must be independent of the value in the data set(only, only to measure more measurement). www.sciencebuddies.orghttps://www.scribbr.com/statistics/standard-deviation/ #:~:text=%20find%20 the standard%20 deviation, square%20 root%20 of %20 the %20 variance.&text=%20learning%20 that%20SD%20 %3D%2013.31, by 2013.31points 20 on 20 on 20 average。Standard Deviations | Step-by-Step Guide by FormulaThe standard deviation is the average amount of variation in the data set. This gives you an average of how far each score is from mean.www.scribbr.comhttps://github.com/joelgrus/data-science-from-scratchjoelgrus/data science from scratch code for data science from Scratchbook. Create an account on GitHub.github.com to help Joel Gross/Data Science evolvejoelgrus/data science from scratch code for data science from Scratchbook. Create an account on GitHub.github.com to help Joel Gross/Data Science evolvejoelgrus/data science from scratch code for data science from Scratchbook. Create an account on GitHub.github.com to help Joel Gross/Data Science evolve